
One step closer to a brain-computer interface: Generative AI decodes images and speech from fMRI recordings
Published on June 03, 2023
This post compares two new research papers that use generative AI techniques to ‘read’ images and text from human brain activity patterns. The first paper generates sentences that subjects heard in podcasts, and the second reconstructs visuals that they were shown — both using only fMRI readings. Together, they show that generative AI techniques can compensate for some limitations of fMRI to capture not only the literal words or pixels perceived but also their semantic meanings.
While these papers were formally published just after generative AI entered the mainstream consciousness through image generation from text (Stability AI, Midjourney, DALL-E), and large language models (ChatGPT), both were conceived in 2022 using older versions of these models. In many ways these papers are variations on the famous ‘I can see what you see’ era work from 2009-2011, with the latent diffusion and large language models now doing the heavy lifting.
Reconstructing text
In Semantic reconstruction of continuous language from non-invasive brain recordings, the researchers train an fMRI-to-paragraph generator for 3 participants, using fMRI data created while subjects listened to 16 hours of podcasts. Their decoder is able to capture the gist of the sentences at a level higher than chance, but the examples in the paper (image below) give the impression that the LLM is relying on its vast training corpora to to autocomplete a faint signal.
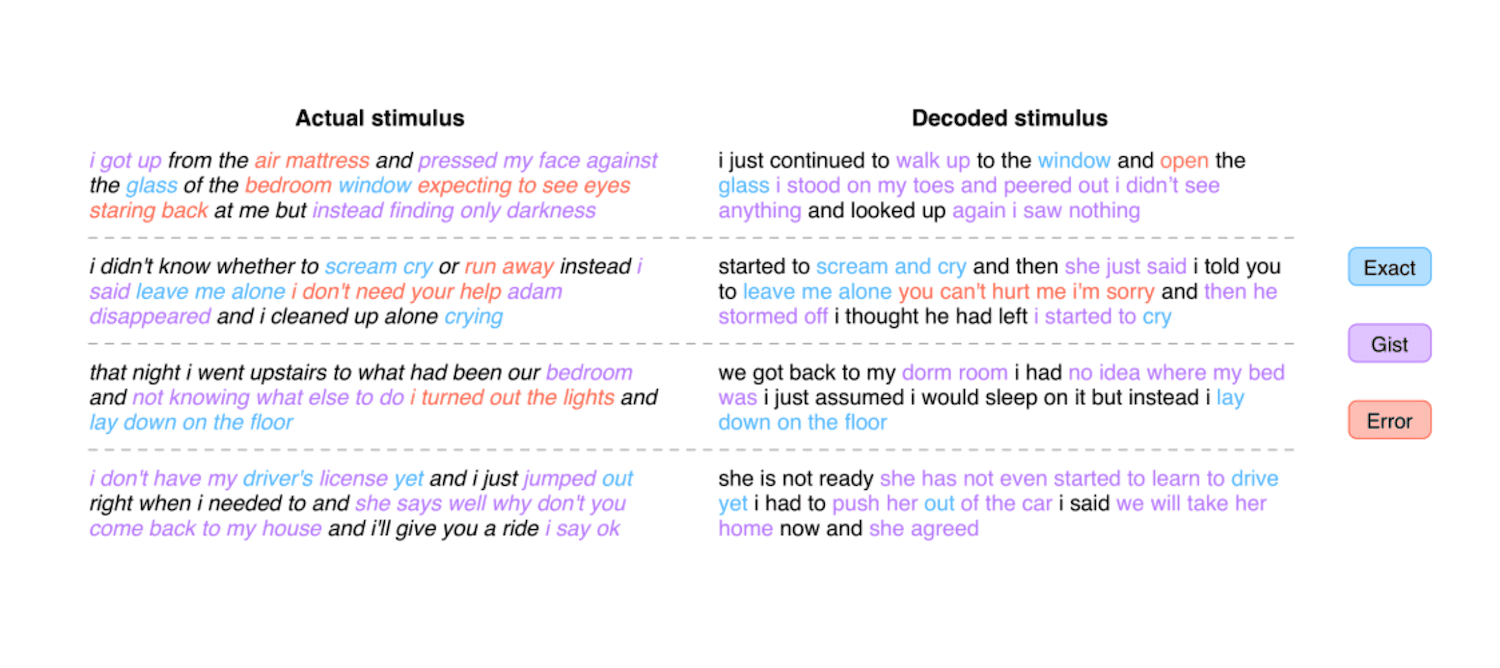
Reconstructing Images
The authors of Stable Diffusion with Brain activity use the open source Stable Diffusion model to reconstruct images from the Natural Scenes fMRI Dataset. They trained models to map from fMRI signals corresponding to the visual and semantic regions of the brain to the image and text components of the latent diffusion models. The results are spectacular, showing that the latent diffusion model combines the two components to produce images that are similar to the original both in meaning and in appearance.

Comparing the papers
| High-resolution image reconstruction with latent diffusion models from human brain activity | Semantic reconstruction of continuous language from non-invasive brain recordings | |
|---|---|---|
| Published | CVPR 2023 | BioRxiv Sep 2022, Nature Neuroscience March 2023 |
| Generative AI model | Stable Diffusion | Original GPT |
| Key contribution | Reconstruction of perceived images from fMRI with much higher semantic and pixel-wise fidelity than previously possible. | First reconstruction of continuous language from fMRI. Prior work used a fixed vocabulary. |
| Individual-specific algorithm training | Yes, all models were built on a per-subject basis | Yes, trained separate model for each participant |
| Brain imaging modality | fMRI | fMRI |
| Dataset description | Used the Natural Scenes dataset of fMRI measurements of 8 healthy adults shown images from CoCo. | fMRI recordings from 3 subjects while listening to listened to 16 hours of podcasts |
| Dataset availability | Openly available through Access Agreement | Not openly available |
| Code available | Soon | Partly |
These recent papers bringing AI and neuroscience worlds closer together were only possible because the 2022 versions of generative AI models were open access (like the Natural scenes fMRI dataset). If we had better neural interfaces (higher bandwidth, more fidelity and better temporal resolution) the models could do a lot more.